

Apache Airflow is an popular open-source orchestration tool having lots of connectors to popular services and all major clouds. This blog post showcases an airflow pipeline which automates the flow from incoming data to Google Cloud Storage, Dataproc cluster administration, running spark jobs and finally loading the output of spark jobs to Google BigQuery.
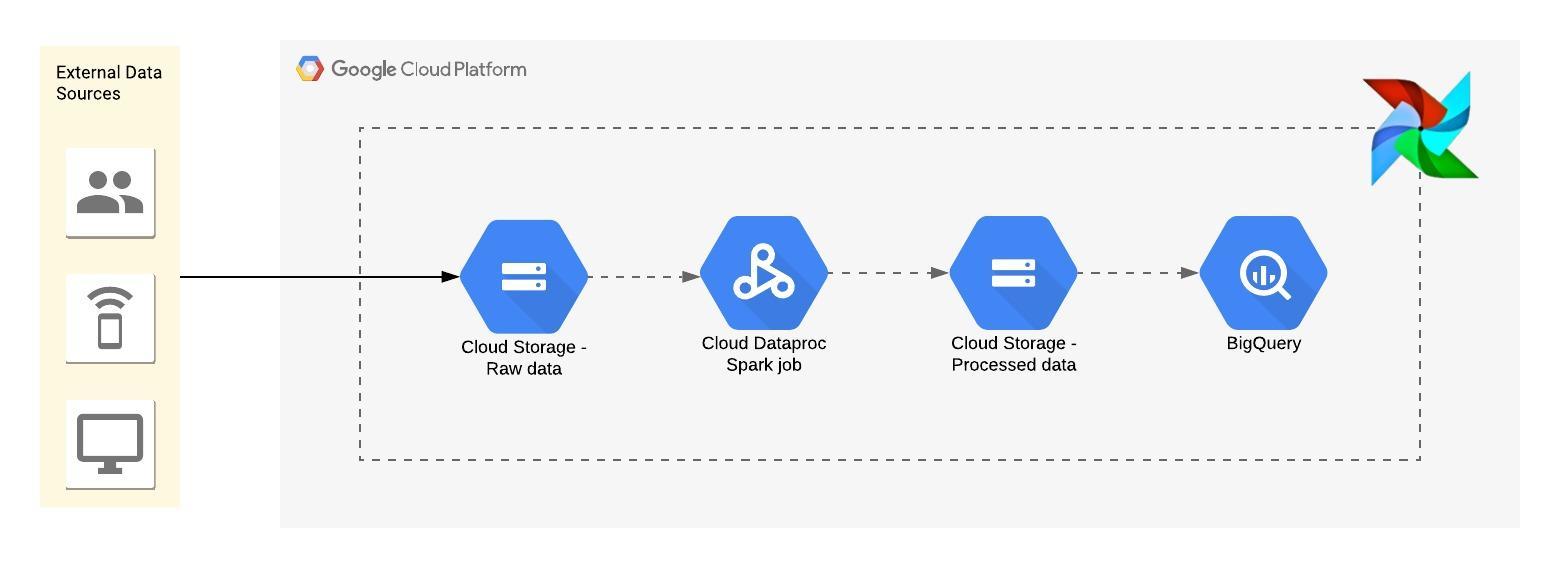
So let’s get started!
You can find the entire python file here. In this blog post, I’ll go through each component.
GCS Prefix check
def dynamic_date(date_offset):
''' subtracts date_offset from execution_date and returns a tuple'''
date_config = "{{ (execution_date - macros.timedelta(days="+str(date_offset)+")).strftime(\"%d\") }}"
month_config = "{{ (execution_date - macros.timedelta(days="+str(date_offset)+")).strftime(\"%m\") }}"
year_config = "{{ (execution_date - macros.timedelta(days="+str(date_offset)+")).strftime(\"%Y\") }}"
return {"date":date_config,"month":month_config,"year":year_config}
def gcs_prefix_check(date_offset):
''' returns string in format YYYY/MM/DD emulating sample directory structure in GCS'''
date_dict = dynamic_date(date_offset)
return date_dict["year"]+"/"+date_dict["month"]+"/"+date_dict["date"]
gcs_prefix_check = GoogleCloudStoragePrefixSensor(
dag=dag,
task_id="gcs_prefix_check",
bucket="example-bucket",
prefix="dir1/dir2"+gcs_prefix_check(3)
) # GoogleCloudStoragePrefixSensor checks GCS for the existence of any BLOB which matches operator's prefix
Sensors in Airflow are operators which usually wait for a certain entity or certain period of time. Few available sensors are TimeDeltaSensor, file, database row, S3 key, Hive partition etc. Our requirement was that the flow should initialize as soon as the raw data is ready in GCS (uploaded by say x provider). Here I have used GCS Prefix Sensor which makes a synchronous call to GCS and checks if there is any BLOB whose URI matches with specified prefix. If yes, the task state becomes success else it waits for certain period of time before rechecking. dynamic_date_ and gcs_prefix_check are helper functions which builds prefix dynamically. dynamic_date function can be used if there is a lag between data arrival and data processing date.
Start and Stop Dataproc Cluster
start_cluster_example = DataprocClusterCreateOperator(
dag=dag,
task_id='start_cluster_example',
cluster_name='example-{{ ds }}',
project_id= "your-project-id",
num_workers=2,
num_preemptible_workers=4,
master_machine_type='n1-standard-4',
worker_machine_type='n1-standard-4c',
worker_disk_size=300,
master_disk_size=300,
image_version='1.4-debian9',
init_actions_uris=['gs://bootscripts-bucket/bootstrap_scripts/bootstrap-gcp.sh'],
tags=['allow-dataproc-internal'],
region="us-central1",
zone='us-central1-c',#Variable.get('gc_zone'),
storage_bucket = "dataproc-example-staging",
labels = {'product' : 'sample-label'},
service_account_scopes = ['https://www.googleapis.com/auth/cloud-platform'],
properties={"yarn:yarn.nodemanager.resource.memory-mb" : 15360,"yarn:yarn.scheduler.maximum-allocation-mb" : 15360},
subnetwork_uri="projects/project-id/regions/us-central1/subnetworks/dataproc-subnet",
retries= 1,
retry_delay=timedelta(minutes=1),
) #starts a dataproc cluster
stop_cluster_example = DataprocClusterDeleteOperator(
dag=dag,
task_id='stop_cluster_example',
cluster_name='example-{{ ds }}',
project_id="your-project-id",
region="us-central1",
) #stops a running dataproc cluster
Dataproc cluster create operator is yet another way of creating cluster and makes the same ReST call behind the scenes as a gcloud dataproc cluster create command or GCP Console. Stop cluster takes existing cluster’s name and deletes the cluster. Airflow uses Jinja templating and parses `` as execution date in YYYYMMDD format wherever used, so we can create cluster names based on when it was created and what data it is processing to have a better management and insight.
Please note that all the parameters available in gcloud command / Console might not be available in Airflow Dataproc operators like adding local-ssds to your cluster during creation. In that case you are better off generating your gcloud dataproc cluster create command and wrapping it with BashOperator in Airflow.
Running Spark job
DATAPROC_SPARK_PROP= {
"spark.jars.packages":"org.apache.lucene:lucene-core:7.5.0,org.apache.lucene:lucene-queries:7.5.0,org.apache.lucene:lucene-spatial:7.5.0,org.apache.lucene:lucene-spatial:7.5.0,org.apache.lucene:lucene-spatial-extras:7.5.0,org.apache.logging.log4j:log4j-core:2.9.0,org.apache.logging.log4j:log4j-api:2.9.0,org.apache.logging.log4j:log4j-slf4j-impl:2.9.0,org.noggit:noggit:0.8,org.locationtech.jts:jts-core:1.15.0,org.locationtech.spatial4j:spatial4j:0.7,org.postgresql:postgresql:42.2.5,com.aerospike:aerospike-client:4.3.0,com.maxmind.geoip2:geoip2:2.4.0,com.google.cloud:google-cloud-storage:1.87.0",
'spark.executor.memoryOverhead':'2g',
'spark.executor.cores':'3',
"spark.executor.memory":'8g',
'spark.master':'yarn',
'spark.driver.userClassPathFirst':'true',
'spark.executor.userClassPathFirst':'true',
'spark.yarn.maxAppAttempts':'1'
} # Dict mentioning Spark job's properties
DATAPROC_SPARK_JARS = ['gs://example-bucket/runnableJars/example-jar.jar']
date_tuple = dynamic_date(3) # Suppose we are processing 3 days ago's data - mimics a lag in arrival and processing of data
run_spark_job = DataProcSparkOperator(
dag=dag,
arguments=["gs://example-source-bucket/year="+date_tuple['year']+"/month="+date_tuple['month']+"/day="+date_tuple['day']+"/*","gs://example-sink-bucket/dir1/year="+date_tuple['year']+"/month="+date_tuple['month']+"/day="+date_tuple['date']+"/"],
region="us-central1",
task_id ='example-spark-job',
dataproc_spark_jars=DATAPROC_SPARK_JARS,
dataproc_spark_properties=DATAPROC_SPARK_PROP,
cluster_name='example-{{ ds }}',
main_class = '[Path-to-Main-Class]',
)
You can make a separate dictionary to mention the spark job’s properties for readability. Dataproc spark operator makes a synchronous call and submits the spark job. The final step is to append the results of spark job to Google Bigquery for further analysis and querying.
load_to_bq = GoogleCloudStorageToBigQueryOperator(
bucket = "example-bucket",
source_objects = ["gs://example-sink-bucket/dir1/year="+date_tuple['year']+"/month="+date_tuple['month']+"/day="+date_tuple['date']+"/*.parquet"],
destination_project_dataset_table = 'project-id.dataset.table',
source_format = 'PARQUET',
write_disposition = 'WRITE_APPEND',
) # Takes a list of GCS URIs and loads it to Bigquery
gcs_prefix_check >> start_cluster_example >> run_spark_job >> stop_cluster_example >> load_to_bq
You can checkout the full code here and more airflow scripts on my repo.